Why a New Programming Language
Imagine you'd like to write a new particle-based fluid algorithm. You started simple, didn't spend much time before finding a reference C++/CUDA work online (or derived the work from your labmate, unfortunately). cmake .. && make, you typed. Oops, cmake threw out an error due to a random incompatible third party library. Installed and rebuilt, now it passed. Then you ran it, which immediately segfaulted (without any stacktrace, of course). Then you started gazing at the code, placed the necessary asset files at the right place, fixed a few dangling pointers and reran. It... actually worked, until you plugged in your revised algorithm. Now another big fight with the GPU or CPU code. More often than not, you get lost in the language details.
If all these sound too familiar to you, congratulations, you are probably looking at the right solution.
Born from the MIT CSAIL lab, Taichi was designed to facilitate computer graphics researchers' everyday life, by helping them quickly implement visual computing and physics simulation algorithms that are executable on GPU. The path Taichi took was an innovative one: Taichi is embedded in Python and uses modern just-in-time (JIT) frameworks (for example LLVM, SPIR-V) to offload the Python source code to native GPU or CPU instructions, offering the performance at both development time and runtime.
To be fair, a domain-specific language (DSL) with a Python frontend is not something new. In the past few years, frameworks like Halide, PyTorch, and TVM have matured into the de facto standards in areas such as image processing and deep learning (DL). What distinguishes Taichi the most from these frameworks is its imperative programming paradigm. As a DSL, Taichi is not so specialized in a particular computing pattern. This provides better flexibility. While one may argue that flexibility usually comes at the cost of not being fully optimized, we often find this not the case for a few reasons:
- Taichi's workload typically does not exhibit an exploitable pattern (e.g., element-wise operations), meaning that the arithmetic intensity is bounded anyway. By simply switching to the GPU backend, one can already enjoy a nice performance gain.
- Unlike the traditional DL frameworks, where operators are simple math expressions and have to be fused at the graph level to achieve higher arithmetic intensity, Taichi's imperative paradigm makes it quite easy to write a large amount of computation in a single kernel. We call it mega-kernel.
- Taichi heavily optimizes the source code using various compiler technologies: common subexpression elimination, dead code elimination, control flow graph analysis, etc. These optimizations are backend neutral, because Taichi hosts its own intermediate representation (IR) layer.
- JIT compilation provides additional optimization opportunities.
That said, Taichi goes beyond a Python JIT transpiler. One of the initial design goals is to decouple the computation from the data structures. The mechanism that Taichi provides is a set of generic data containers, called SNode (/ˈsnoʊd/). SNodes can be used to compose hierarchical, dense or sparse, multi-dimensional fields conveniently. Switching between array-of-structures and structure-of-arrays layouts is usually a matter of ≤10 lines of code. This has sparked many use cases in numerical simulation. If you are interested to learn them, please check out Fields (advanced), Spatially Sparse Data Structures, or the original Taichi paper.
The concept of decoupling is further extended to the type system. With GPU memory capacity and bandwidth becoming the major bottlenecks nowadays, it is vital to be able to pack more data per memory unit. Since 2021, Taichi has introduced customizable quantized types, allowing for the definition of fixed point or floating point numbers with arbitrary bits (still needs to be under 64). This has allowed an MPM simulation of over 400 million particles on a single GPU device. Learn more details in the QuanTaichi paper.
Taichi is intuitive. If you know Python, you know Taichi. If you write Taichi, you awaken your GPU (or CPU as a fallback). Ever since its debut, this simple idea has gained so much popularity, that many were attracted to contribute new backends, including Vulkan, OpenGL and DirectX (working in progress). Without our strong and dedicated community, Taichi would never have been where it is now.
Going forward, we see many new opportunities lying ahead, and would like to share some of our vision with you.
Academia
90% of the research code will be trashed due to the nature of research where assumptions keep being broken and ideas keep being iterated. Swiftly coding without thinking too much about performance may lead to incorrect conclusions, while pre-matured code optimization can be a waste of time and often produces a tangled mess. The high performance and productivity are, therefore, extremely helpful for research projects.
Taichi will keep embracing the academia. The key features we have (or plan to have) for high-performance computing research projects include small-scale linear algebra (inside kernels), large-scale sparse systems, and efficient neighbor accessing for both structured and unstructured data.
Taichi also provides an automatic differentiation module via source code transformation (at IR level), making it a sweet differentiable simulation tool for machine learning projects.
Apps & game engine integration
One huge advantange of Taichi lies in its portability, thanks to the support for a wide variety of backends. During the development process, we have also recognized the increasing demands from our industry users for multi-platform packaging and deployment. Below shows an experimental demo of integrating Taichi with Unity. By exporting Taichi kernels as SPIR-V shaders, we can easily import them into a Unity project.
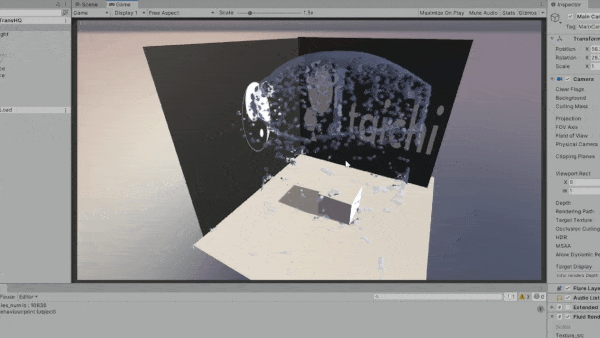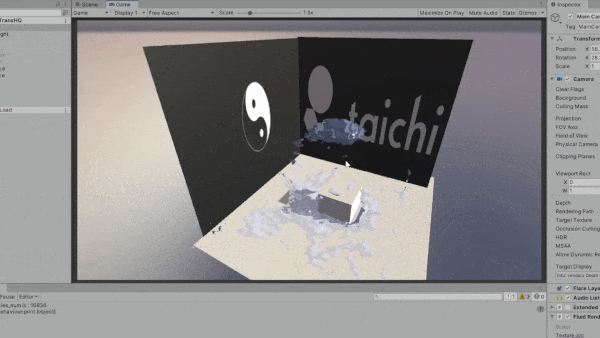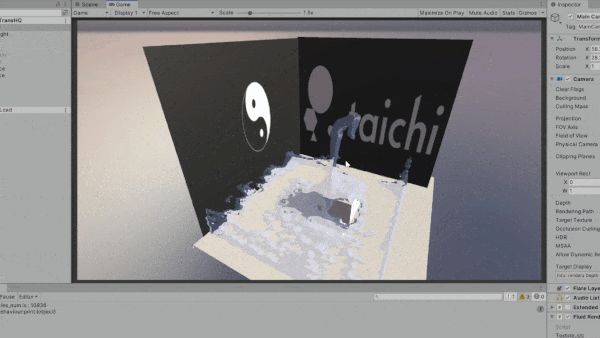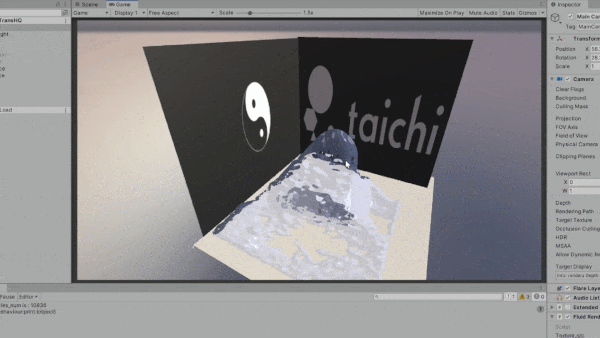
General-purpose computing
While originally designed for physics simulation, Taichi has found its application in many other areas that can be boosted by GPU general-purpose computing.
- taichimd: Interactive, GPU-accelerated Molecular (& Macroscopic) Dynamics using the Taichi programming language
- TaichiSLAM: a 3D Dense mapping backend library of SLAM based Taichi-Lang, designed for the aerial swarm.
- Stannum: Fusing Taichi into PyTorch.
Maybe a new frontend?
The benefit of adopting the compiler approach is that you can decouple the frontend from the backend. Taichi is currently embedded in Python, but who says it needs to stay that way? Stay tuned :-)